1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
| struct BBParg {
int *empty, *mutex, *full, id;
int *con_mutex;
struct FIFO32 *fifo;
struct TASK *task;
};
void producer(struct BBParg *args) {
avoid_sleep();
int *empty = args->empty,
*mutex = args->mutex,
*full = args->full,
id = args->id;
struct FIFO32 *fifo = args->fifo;
struct TASK *task = args->task;
int cnt = 2, i;
char tag;
char str[128];
while (1) {
tag = 0;
while (!tag) {
tag = 1;
for (i = 2; i * i <= cnt; i++) {
if (cnt % i == 0) {
tag = 0;
break;
}
}
if (!tag) cnt++;
if (cnt > 0x3f3f3f) cnt = 2;
}
sem_wait(empty);
sem_wait(mutex);
fifo32_put(fifo, cnt++);
sem_signal(mutex);
sem_signal(full);
}
}
void consumer(struct BBParg *args) {
avoid_sleep();
int *empty = args->empty,
*mutex = args->mutex,
*full = args->full,
id = args->id,
*con_mutex = args->con_mutex;
struct FIFO32 *fifo = args->fifo;
struct TASK *task = args->task;
int tmp;
char str[128];
while (1) {
while (task->cons == 0)
io_hlt();
sem_wait(full);
sem_wait(mutex);
tmp = fifo32_get(fifo);
sem_signal(mutex);
sem_signal(empty);
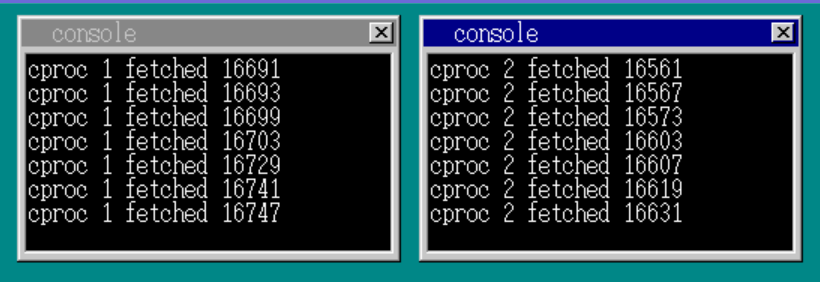
sprintf(str, "cproc %d fetched %d\n", id, tmp);
sem_wait(con_mutex);
cons_putstr0(task->cons, str);
sem_signal(con_mutex);
}
}
struct SHEET *sout;
sout = open_console(shtctl, memtotal);
sheet_slide(sout, 64, 4);
sheet_updown(sout, shtctl->top);
struct BBParg agp, agc1, agc2;
int buf[128];
struct FIFO32 bbpfifo;
fifo32_init(&bbpfifo, 8, buf, 0);
struct TASK *tskp, *tskc1, *tskc2;
int empty = 8, mutex = 1, full = 0;
int con_mutex = 1;
agp.empty = ∅
agp.full = &full;
agp.mutex = &mutex;
agp.fifo = &bbpfifo;
agp.con_mutex = &con_mutex;
agc1 = agc2 = agp;
agc1.id = 1;
agc2.id = 2;
agc1.task = key_win->task;
agc2.task = sout->task;
tskp = create_task(memman, &producer, (void*)&agp);
tskc1 = create_task(memman, &consumer, (void*)&agc1);
tskc2 = create_task(memman, &consumer, (void*)&agc2);
task_run(tskp, 2, 0);
task_run(tskc1, 2, 0);
task_run(tskc2, 2, 0);
|